Hybrid Paper Recommendation
System
MILESTONE
Zheyu Liu, Huizhe Li & Wenyuan Feng
Introduction:
Most graduate
students may have such troubles: when you want to learn more about a special
field which you are interested in and would like to read some papers about it, you
may find it is hard to find out the relevant papers among tons of papers and
information in library or on the Internet. In this project, we try to determine
those papers that are most likely to be of a user’s interest among all
candidate papers. This is a recommendation system based on users’ recent actions.
Dataset:
The data that we
use to simulate the real scenes and actions is gotten from ACL ARC
(http://acl-arc.compnus.edu.sg). There are 597 candidate papers to recommend,
and 18 profiles of users who were asked to read all the 597 papers and marked
those of their interest as ‘relevant’. All the data is based on real experiments.
Data example:
User example

Model:
Since each user
has his own interests and marks for different papers,
our model is a user-based model and has combined some different ways to do the
recommendation.
For each given
user, we will calculate the rating of a candidate paper i
based on the features of our concern: authors, key words and references. We
preserve some hash maps for each user to record his favorite authors, titles,
keywords and references.
We use the
following expression to calculate the estimate relevance of one user for each
paper:
![]() (i) =
(i) = ![]() ・
・
![]() (i) +
(i) + ![]() ・
・![]() (i) +
(i) + ![]() ・
・![]() (i)
(i)
In this formula,
![]() : user-specific hyper-parameters.
: user-specific hyper-parameters.
![]() : match score
obtained by comparing features of paper i
and learned
user preference.
: match score
obtained by comparing features of paper i
and learned
user preference.
To calculate S, we
need to extract information reflecting a user’s preference(for authors, key
words and references) from papers that are marked as relevant by that user. So
we get out the training data and calculate the key terms of the relevant papers
to get the different Su for users.
This
is the detail about how to calculate Su:
For
each author aI, we have
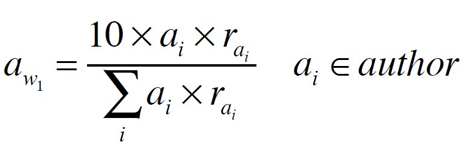
In this formula, awi is used to represent the score of an author ai for a particular user after training. rai is used to record
the score of this author―either it is relevant or not.
It is a little
more complicated to get the different parameters for wu.
It is hard to define which items in authors, keywords and references should be
valued the most since different users may have different preferences. Some of
the users may like an author very much and like all the papers he wrote, but
some of users may just like some special points in keywords. So we take the
variance into consideration. If the user likes only one or few authors and then
the variance of the authors should be bigger than others at the same time,
which means he has a very obvious preference on author-item, we should give the
author item more weight. But if the user does not care about the authors, which
means he likes a lot of authors and each author has a same but not high score
and the variance of authors will not be very big, we should not give the author
item too much weight.
This formula is
used to calculate the parameter after the variance weight.
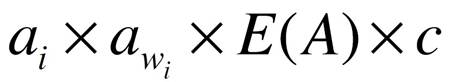
In this formula, E(A) is A’s variance factor, c is a constant.
Result:
To test our
experiment result, we give ratings of two papers that are marked as relevant by
that user and all the papers that are irrelevant for each user. We try to find
out if the given relevant papers would get a high rank among those unknown
papers.
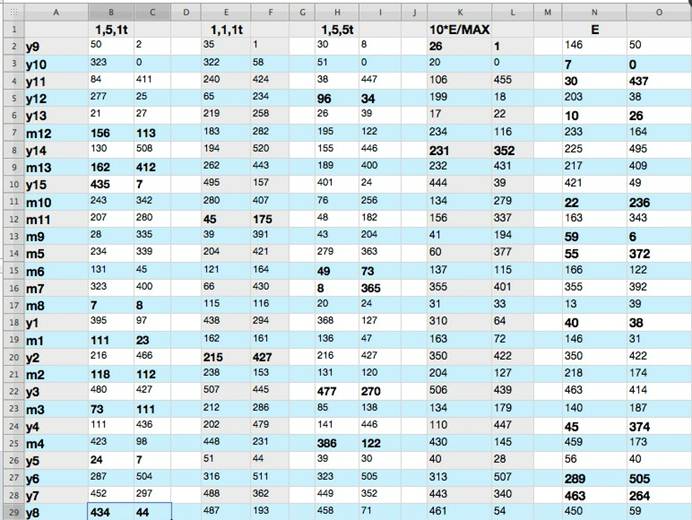
The table blow is
our result. The first column is user name, and column B and C is the rank of
the two given relevant papers, so are the column E and F, and column H and I.
the difference between {B,C}, {E,F} and {H,I} is different weight of authors, keywords
and references. The column {N,O} is the rank of the
two given papers after taking variance into account. Column {K,L} is the rank of considering both variance and maximum of
the parameters.
The bold numbers
are the best performance of different models.
This is some
detail performance of our model for one user:
User 1:
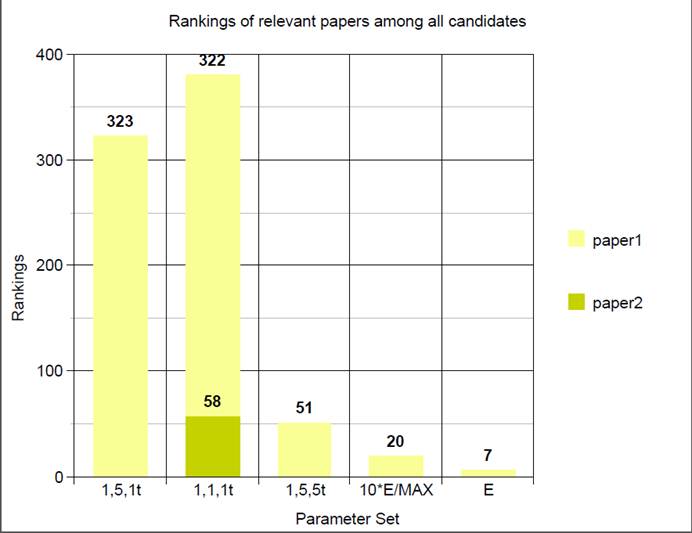
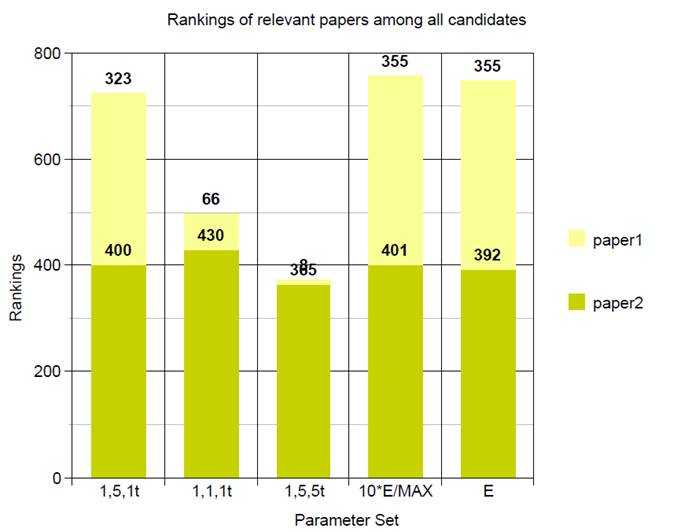
User 2:
User 3:
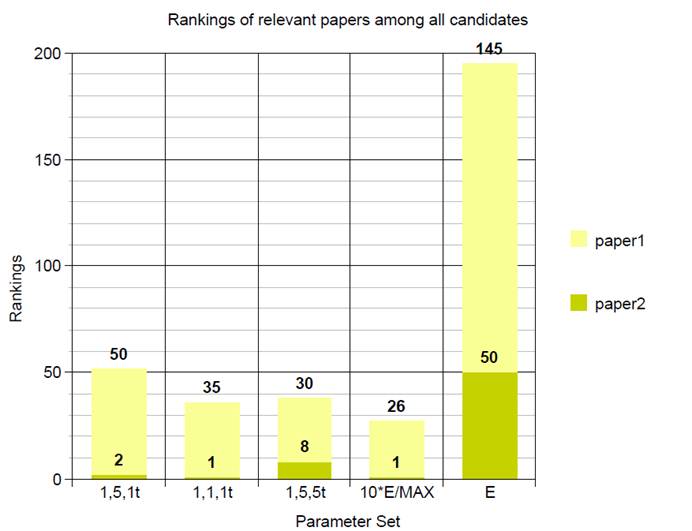
By the above performance
and result, we can see that it is hard to determine which parameter should be
thought highly of. It depends on different customs and preferences of different
users. But generally, the performance of regarding the variance will not be too
bad.
Future work:
One of the most
important things we should do is to tune hyper-parameters tuning through
statistical analysis. We are thinking about if there’s any situation that may
affect the accuracy of our model.
The second thing
we should do is to obtain rich training data since the correct forecast result should
be based on the large number of training set.
The last thing we
can do is to build web-based user interface to make our recommender system more
friendly and useful.
Reference:
Y. Sun, W. Ni and
R. Men A personalized paper
recommendation approach based on web paper mining and reviewer’s interest
modeling 2009 International Coference on Research
Challenges in Computer Science, Tianjin China
C. Basu, H. Hirsh, W. Cohen & C. Manning Technical Paper Recommendation: A study in Combining Multiple
Information Sources 2001 Journal of Artificial Intelligence Research
K. Sugiyama &
M. Kan Scholarly
Paper Recommendation via User’s recent research interests https://www.comp.nus.edu.sg/~kanmy/papers/JCDL10-CRfinal.pdf